
Итак, ответ на вопросы успешно найден в комментариях. Т.к. на картинке датасет выстроился почти в непрерывную кривую, разность между координатами соседних текстов оказалась всегда маленькой. Это значит, что и в исходных признаках при переходе от текста к тексту признаки изменялись лишь чуть-чуть.
Очевидный способ достижения этого результата - забыть обнулять счетчики частот слов, что и сделал студент, о чем и догадался научрук. Пассаж про изучение библиотек был, конечно же, о том, что в sklearn есть готовые текстовые векторизации, которые можно взять из коробки и не накосячить таким образом. Тот факт, что студент забыл обнулять счетчики, проверяется легко: достаточно посмотреть на матрицу признаков, ведь к последнему тексту нулей уже, конечно же, не осталось.
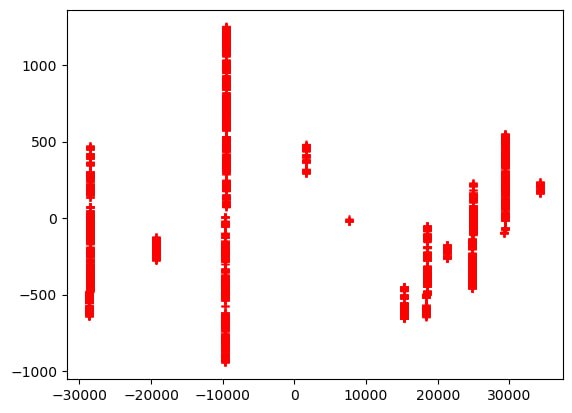
Почему же возникали разрывы? Из-за плохой предобработки текстов были тексты с большим количеством всяких спецсимволов и слов, которые давали очень большой прирост к криво выделенным токенам. В частности, картина из предыдущего поста - это еще после фильтрации части таких спецтекстов. Без фильтрации получалась та, которую вы видите в прикрепленных к посту
Очевидный способ достижения этого результата - забыть обнулять счетчики частот слов, что и сделал студент, о чем и догадался научрук. Пассаж про изучение библиотек был, конечно же, о том, что в sklearn есть готовые текстовые векторизации, которые можно взять из коробки и не накосячить таким образом. Тот факт, что студент забыл обнулять счетчики, проверяется легко: достаточно посмотреть на матрицу признаков, ведь к последнему тексту нулей уже, конечно же, не осталось.
Почему же возникали разрывы? Из-за плохой предобработки текстов были тексты с большим количеством всяких спецсимволов и слов, которые давали очень большой прирост к криво выделенным токенам. В частности, картина из предыдущего поста - это еще после фильтрации части таких спецтекстов. Без фильтрации получалась та, которую вы видите в прикрепленных к посту
🔥21👍8❤🔥5❤2
tg-me.com/kantor_ai/377
Create:
Last Update:
Last Update:
Итак, ответ на вопросы успешно найден в комментариях. Т.к. на картинке датасет выстроился почти в непрерывную кривую, разность между координатами соседних текстов оказалась всегда маленькой. Это значит, что и в исходных признаках при переходе от текста к тексту признаки изменялись лишь чуть-чуть.
Очевидный способ достижения этого результата - забыть обнулять счетчики частот слов, что и сделал студент, о чем и догадался научрук. Пассаж про изучение библиотек был, конечно же, о том, что в sklearn есть готовые текстовые векторизации, которые можно взять из коробки и не накосячить таким образом. Тот факт, что студент забыл обнулять счетчики, проверяется легко: достаточно посмотреть на матрицу признаков, ведь к последнему тексту нулей уже, конечно же, не осталось.
Почему же возникали разрывы? Из-за плохой предобработки текстов были тексты с большим количеством всяких спецсимволов и слов, которые давали очень большой прирост к криво выделенным токенам. В частности, картина из предыдущего поста - это еще после фильтрации части таких спецтекстов. Без фильтрации получалась та, которую вы видите в прикрепленных к посту
Очевидный способ достижения этого результата - забыть обнулять счетчики частот слов, что и сделал студент, о чем и догадался научрук. Пассаж про изучение библиотек был, конечно же, о том, что в sklearn есть готовые текстовые векторизации, которые можно взять из коробки и не накосячить таким образом. Тот факт, что студент забыл обнулять счетчики, проверяется легко: достаточно посмотреть на матрицу признаков, ведь к последнему тексту нулей уже, конечно же, не осталось.
Почему же возникали разрывы? Из-за плохой предобработки текстов были тексты с большим количеством всяких спецсимволов и слов, которые давали очень большой прирост к криво выделенным токенам. В частности, картина из предыдущего поста - это еще после фильтрации части таких спецтекстов. Без фильтрации получалась та, которую вы видите в прикрепленных к посту
BY Kantor.AI

Share with your friend now:
tg-me.com/kantor_ai/377